+100宝石
+100宝石

加入 Mergeek 福利群
扫码添加小助手,精彩福利不错过!
若不方便扫码,请在 Mergeek 公众号,回复 群 即可加入
- 精品限免
- 早鸟优惠
- 众测送码

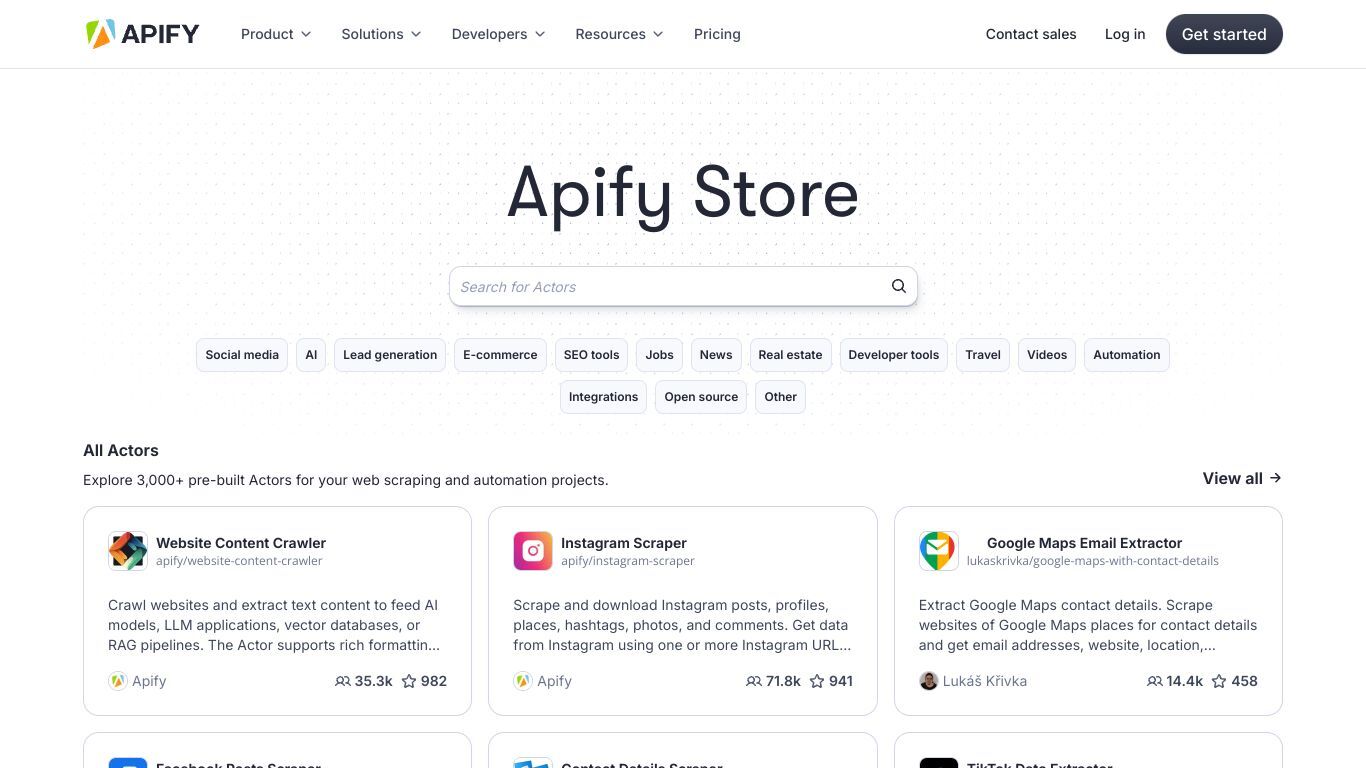
Apify: Full-stack web scraping and data extraction platform
 分享
分享









这款云端平台专为网络爬虫、浏览器自动化及人工智能数据设计。提供3000+预构建工具与代码模板,支持定制服务。核心功能包括无服务器程序构建、与多应用服务集成、数据存储、防阻断技术、代理功能及开源库Crawlee。适用于企业、初创公司、大学及非营利组织,支持生成AI数据、线索生成、市场研究及情感分析等多种应用场景。